
[자료 구조 #7] 해시 테이블(Hash Table)
기회는 준비된 자에게 온다 !
해시의 정의
해시(Hash) 구조란 무엇일까?
키(key)와 값(value)의 쌍으로 이루어진 데이터 구조를 일컫는다.
파이썬으로 치면 dictionary라는데 C++을 주로 사용해본 나로서는 직관적으로 와닿지 않는다.
해시라는 자료구조 이름이 있는 것이 아니라, 정확히 해시라고 하는 것은 임의의 값을 고정 길이로 변환하는 작업을 뜻한다.
아래 사진으로 자세히 정리한다.
해시와 관련된 몇 가지 용어
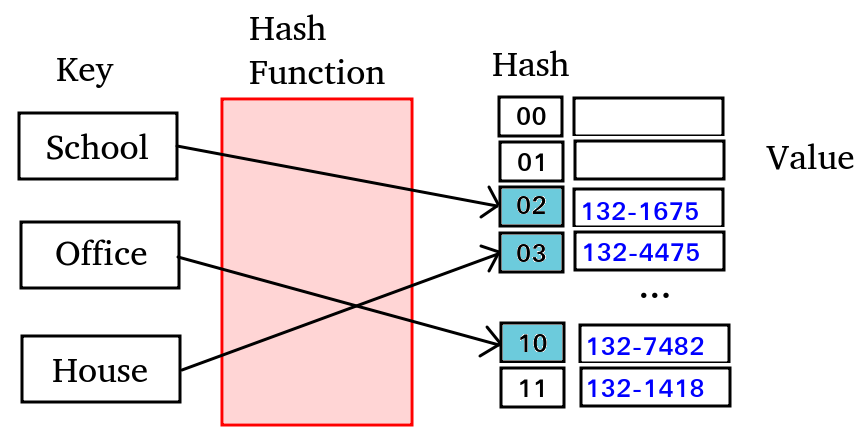
- 키 (Key) : 해시 함수(Hash Function)의 input이 되는 고유한 값
- 해시 (Hash) : 임의의 값을 고정 길이로 변환하는 것
- 해시 테이블 (Hash Table) : key 값의 연산에 의해 직접 접근이 가능한 데이터 구조
- 버킷 (Bucket) 또는 슬롯 (Slot) : 해시 테이블에서 하나의 데이터가 저장되는 공간
- 해시 함수 (Hashing Function) : key 값에 대해 연산을 통해 데이터(value)의 위치를 찾는 함수
그림에서 school, office, house 같은 입력 값이 들어왔을 때 해쉬 함수를 이용해서 정수값으로 변환하여 버킷에 저장한 것을 볼 수 있다.
이 과정을 다른 말로 해싱(Hashing)이라고 부르기도 한다.
따라서 입력 데이터(key)와 변환된 정수 값(value)의 쌍으로 저장하는 자료 구조를 해시 테이블(Hash Table)이라고 부른다.
파이썬 딕셔너리 예제를 들고 왔는데, 해시 테이블은 아래와 같이 사용된다고 볼 수 있다.
person_dict = {'name' : 'bigbigpark', 'height' : 178, 'weight' : 75}
이 때 왼쪽에 있는 것이 key 값인데, 인덱스로 검색하는 것이 아닌 키값으로 O(1)로 자료 읽기가 가능하다.
해시 테이블의 기능
뒤에 설명할 해시 충돌(Hash Collision)이 없다는 가정하에,
- 데이터 삽입
- key값을 hash function을 이용하여 hash로 변경
- 미리 준비해둔 저장소(bucket, slot) 중 알맞는 hash 값을 찾아 value를 저장
- 삽입 과정의 시간 복잡도는 O(1)
- 데이터 삭제
- buncket에서 삭제하려고 하는 key와 매칭이 되는 value를 찾아 삭제함
- 삭제 과정의 시간 복잡도는 O(1)
- 데이터 검색
- key값을 hash function을 이용하여 hash를 찾고 해당 value 검색 가능
- 검색 과정의 시간 복잡도는 O(1)
해시 테이블의 장단점
해시 테이블은 데이터 검색, 삽입, 삭제가 많이 필요한 경우에 자주 사용된다.
하지만 hash 값들을 저장할 공간(bucket)을 지정해야 하므로 일반적으로 많은 저장 공간이 요구된다.
또 여러 key에 해당하는 hash(주소 개념)이 동일한 경우 해시 충돌(Hash Collision)이 발생한다.
해시 충돌
해시 충돌이란 위에서 언급되었듯 여러 key에 의한 중복된 해시에 의해서 나타난다.
사실 비둘기집의 원리에 의해 해시기반 자료구조에서는 불가피한 일이다.
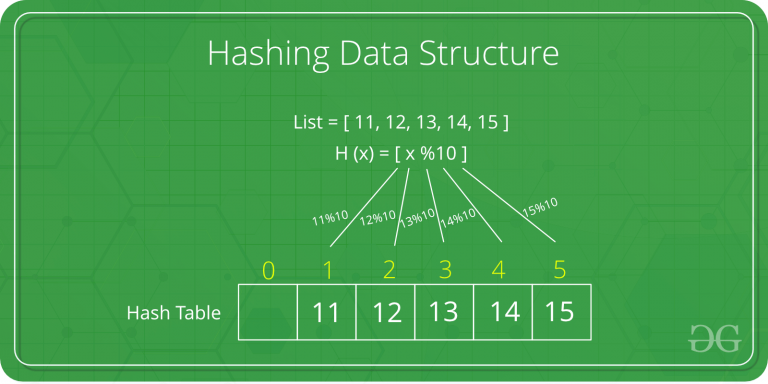
위의 사진에서 H(x)는 해시 함수를 말한다. 일반적인 경우 해시 함수를 곱셈법 혹은 나눗셈법을 이용하여 정의하기도 한다. 그림에 있듯이 나머지 연산으로 정의 하게 되면 List=[11, 12, 13, 14, 15, 21, 22, 23, 24, 25]일 때 충돌이 불가피한 것을 예상할 수 있다.
해시 충돌의 해결
1) Chaining
연결 리스트 기반 Chaining 방법을 이용해서 해시 충돌 문제를 해결할 수 있다.
Chaining 방법은 hash 함수의 결과 값인 동일한 bucket에 저장하되 원래 저장되어 있던 value의 next로 연결하는 형태로 저장하는 방법을 말한다.
직관적으로 충돌 해결을 할 수 있지만 검색 연산에 있어 연결 리스트를 처음부터 하나씩 찾아야 하므로 최악의 경우 시간 복잡도가 O(n)까지 증가할 수 있다는 단점이 있다.
2) Open Addressing
다른 말로 close hashing, linear probing이라고 부르기도 한다.
이 방법은 충돌이 일어날 경우, 비어있는 hash를 찾아 데이터를 저장하는 기법이다.
따라서 chaining 기법은 하나의 hash에 여러 value들이 저장된 구조인 반면, open addressing 에서는 무조건적으로 key-value는 1:1 매칭이 된다.
이 때 충돌이 일어나는 hash 기준 양옆 한칸씩 보며 빈 공간을 찾아가는 기법을 linear probing이라고 하는데, 이 기법은 특정 위치에만 밀집하는 clustering 문제가 발생할 수 있다.
따라서 n^2으로 이동하며 빈 공간을 찾아가는 quadratic probing 기법도 존재한다.
3) Double Hasing
해시 충돌이 발생할 경우 또 다른 해시 함수를 사용하여 증가 폭을 구한다. 증가폭만큼 인덱스를 증가시키며 비어있는 곳을 탐색하는 방법이다.
3) 해시 함수 개선
다양한 해시 함수가 있고, 변형도 너무 많다. 그 중 일반적으로 사용되는 것 중에 나눗셈법이 존재한다.
- 나눗셈법
- 이 방법은 미리 해시 테이블의 크기 N을 아는 경우에 사용 가능하다.
- H(x) = x mod N
- 이 때 N은 2의 k제곱 꼴을 사용하면 안 된다. 왜냐하면 하위 k비트를 고려하지 않기 때문이다.
- 결국… 소수가 짱인가?
해시 함수 언제 쓰는데?
- 전화번호부
- 핸드폰 연락처를 생각했을 때, 저장할 때는 사람의 이름+관련 전화번호를 추가한다.
- 추후 이름만 검색해도 저장된 이름 및 전화번호에 대한 정보를 준다.
- 메뉴판
- 메뉴 이름과 가격을 추가한다.
- 추후 메뉴 이름만 검색을 하면 메뉴와 가격을 알려주는 메뉴판도 만들 수 있다.
- 중복된 항목 방지
- 투표소에서 누가누가 투표를 했는 지 안 했는지 판단하기 위해서 사용될 수 있다.
- 배열이나 리스트를 사용하게 되면 O(N)이 소요되기 때문이다.
- 입력에 이름을 입력했을 때 해시 테이블에 이름이 있는 지 없는 지 바로 알 수 있다.
해시 테이블 함수 기능
insert(std::pair<first,second>)- key-value 쌍을 해시 테이블에 삽입한다.
- 이 때 이미 등록된 key가 있다면 무시된다. ([ ] 인덱스로 덮어쓰기 가능)
erase(key)- key를 해시 테이블에서 삭제한다.
- key를 찾지 못하면 제일 끝 반복자인
end()를 호출한다
count(key)- key 값에 해당하는 원소들의 개수 리턴
size()- 해시 테이블에 저장된 key-value 쌍의 개수 리턴
해시 테이블 사용 예시 (C++, STL)
C++의 STL에서는 대표적인 해시 맵이 두 가지 있다.
std::map- tree 기반으로 구현된다
- key를 기준으로 오름차순으로 자동 정렬
- 시간복잡도 O(log N)
std::unordered_map- hash 기반으로 구현된다
- 특별한 정렬 절차가 없다
- 시간 복잡도 O(1)
사실 원소의 순서가 중요하지 않을 때 사용하는 해시 테이블 자료 구조 특성상 std::map은 필요 없는듯.
그리고.. 중복된 원소는 insert 시 무시된다 ㅠ
기본 선언
아래 <unordered_map>을 인클루드 해주고 main 함수에서 아래와 같이 사용할 수 있다.
#include <iostream>
#include <unordered_map>
int main()
{
std::unordered_map<std::string, int> hash_table;
return 0;
}
사용법
반드시 해시 테이블에 선언했던 자료형 쌍으로 입력해주자.
make_pair<first, second>를 이용하면 쉽게 insert할 수 있다.
이 때 중복을 허락하지 않는다. 따라서 제일 처음에 넣은 “Eric”-27 만 해시 테이블에 매핑된다.
// 삽입
hash_table.insert(std::make_pair<std::string,int>("Eric", 27));
hash_table.insert(std::make_pair<std::string,int>("Amanda", 10));
hash_table.insert(std::make_pair<std::string,int>("Eric", 100));
하지만 아래와 같이 강제로 덮어쓰기 할 수 있다.
이 경우 “Eric”이 해시 테이블에 없다면 새로 추가하는 경우가 생기니… 반드시 find()로 검사하는 프로세스를 추가하자.
hash_table["Eric"] = 99;
// 삭제, 키가 없을 시 end() 반환
hash_table.erase("Amanda");
// 출력
for (const auto& iter : hash_table)
{
std::cout << iter.first << " : " << iter.second << std::endl;
}
중복 가능 해시 테이블 사용 예시 (C++, STL)
앞서 봤던 <unordered_map>은 insert 동작 시 중복을 무시하였다.
하지만 multimap을 이용하여 중복 가능한 해시 테이블 예시로 사용할 수 있다.
<map> 안에 포함되어 있다.
기본 선언 및 삽입
#include <iostream>
#include <map>
int main()
{
std::multimap<std::string, int> hash_table;
hash_table.insert(std::make_pair<std::string, int> ("Eric", 10) );
hash_table.insert(std::make_pair<std::string, int> ("Eric", 20) );
hash_table.insert(std::make_pair<std::string, int> ("Eric", 30) );
hash_table.insert(std::make_pair<std::string, int> ("Eric", 40) );
std::cout << hash_table.count("Eric") << std::endl;
return 0;
}
// 이 문장 빌드가 안 될 것이다.
// 어떤 것을 반환해야할 지 몰라서
std::cout << hash_table.find("Eric") << std::endl;
검색
// equal_range는 중복된 해시 값에 대한 시작 반복자(begin)와
// 마지막 반복자 (second)를 std::pair 형태로 반환한다.
auto range = hash_table.equal_range("Eric");
for (auto iter = range.first; iter != range.second; ++iter)
{
std::cout << iter->first << " : " << iter->second << std::endl;
}
그 출력은 아래와 같다
Eric : 10
Eric : 20
Eric : 30
Eric : 40
내가 만든 구조체를 이용한 해시 테이블을 만들고 싶을 때
아쉽지만… 해시 함수를 직접 구현하는 수 밖에 없다.
Leave a comment