
[자료 구조 #8] 트리(Tree)
기회는 준비된 자에게 온다 !
트리의 개념
트리(Tree)란 노드들이 나무 가지처럼 연결된 비선형 계층적 자료구조다.
큰 주제로 보면 그래프의 일종으로, 한 노드에서 시작해 다른 정점들을 순회하여 자기 자신에게 돌아오는 순환이 없는 연결 그래프이다. 하지만 이번 글에서는 트리에 대해서만 정리한다.
트리는 아래 사진과 같이 나무 모양을 거꾸로 뒤집은 듯하게 생겼다.
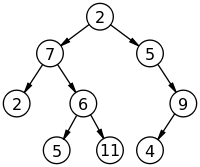
트리의 특징
- 하나의 루트 노드를 가진다.
- 루트 노드는 0개 이상의 자식 노드를 갖는다.
- 자식 노드 또한 0개 이상의 자식 노드는 갖는다.
- 노드들과 그것들을 연결하는 간선들로 구성이 되어 있다.
- 트리에는 사이클이 없다.
- 사이클이란 한 노드에서 출발하여 다른 노드를 거쳐 다시 원래 노드로 돌아오는 것을 말함.
- 따라서 트리는 사이클(cycle)이 없는 하나의 연결 그래프(connected graph)라고 할 수 있다.
트리와 관련된 용어
- 루트 노드(root node) : 트리에서 최상위 노드를 일컫음. 트리는 단 하나의 루트 노드만 존재
- 단말 노드(leaf node) : 자식이 없는 노드이며 다른 말로 ternimal 노드라고 불림
- 내부 노드(internal node) : 단말 노드가 아닌 노드
- 간선(edge) : 노드를 연결하는 선
- 형제(sibling) : 같은 부모 노드를 갖는 노드들
- 깊이(depth) : 루트 노드에서 어떤 노드에 도달하기 위해 거쳐야 하는 간선의 수
- 레벨(level) : 트리의 특정 깊이를 가지는 노드의 집합
- 차수(degree) : 자식 노드의 개수
- 트리의 차수(degree of tree) : 트리의 최대 차수
트리의 종류
1. 이진 트리
이진 트리(Binary Tree)는 각 노드가 최대 두 개의 자식을 갖는 트리를 뜻한다.
즉, 각 노드는 자식이 없거나 한 개이거나 두 개만을 갖는 것이다.
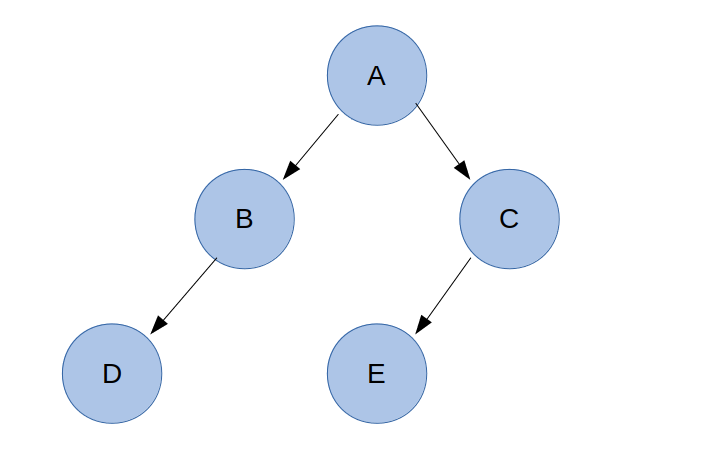
2. 완전 이진 트리
완전 이진 트리(complete binary tree)는 마지막 레벨을 제외하고 모든 레벨이 완전히 채워져있다.
마지막 레벨은 꽉 차 있지 않아도 되지만, 노드가 왼쪽에서 오른쪽으로 채워져야 한다.
아래는 완전 이진 트리의 예시다.
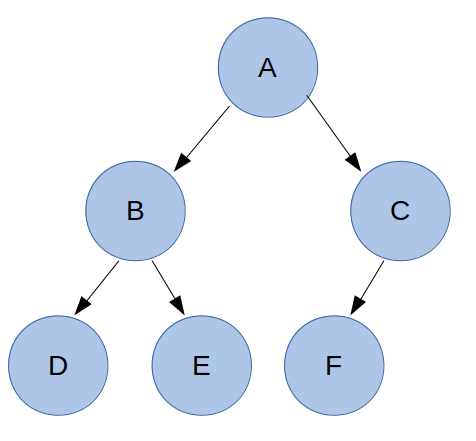
아래는 완전 이진 트리가 아니다.
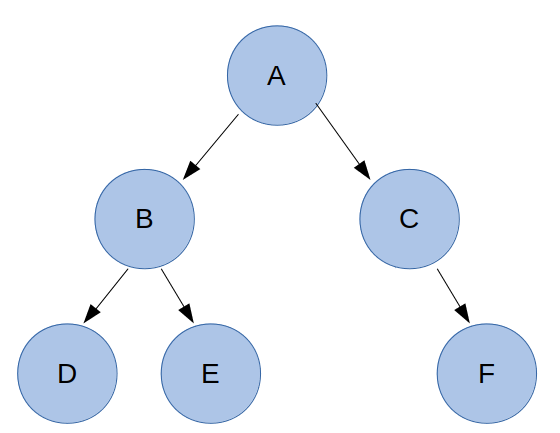
이것 외에도 전 이진 트리(Full Binary Tree)와 포화 이진 트리(Perfect Binary Tree)가 존재한다.
3. 이진 탐색 트리
이진 탐색 트리(Binary Search Tree)는 이진 트리이면서 아래 속성을 갖는 트리를 뜻한다.
- 노드에 저장된 키(key)는 유일하다.
- 부모의 key가 왼쪽 자식 노드의 key보다 크고 오른쪽 자식 노드의 key보다 작다.
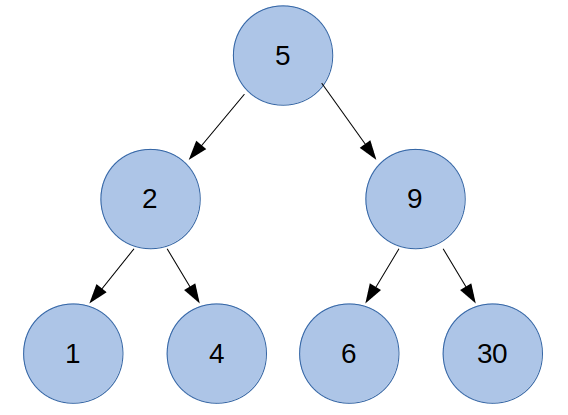
아마 KD-Tree가 이진 탐색 트리를 베이스로 하는 것 같다.
트리 순회
트리 순회(Tree Traversal)란 트리의 각 노드를 체계적인 방법으로 탐색하는 과정을 의미한다.
노드를 탐색하는 순서에 따라 아래와 같이 나뉜다.
- 전위 순회(preorder traversal)
- 중위 순회(inorder traversal)
- 후위 순회(postorder traversal)
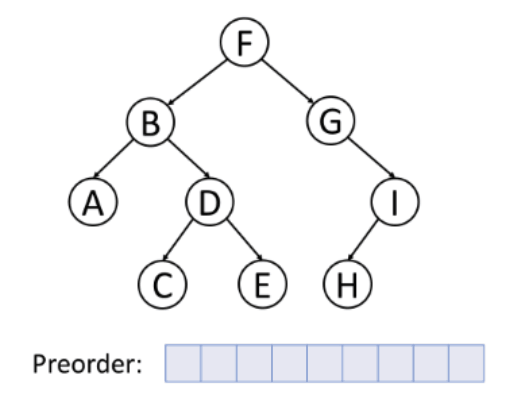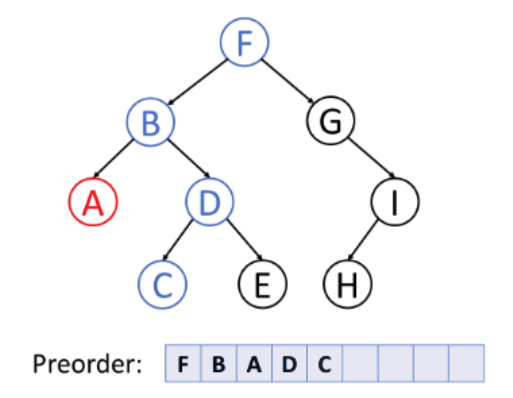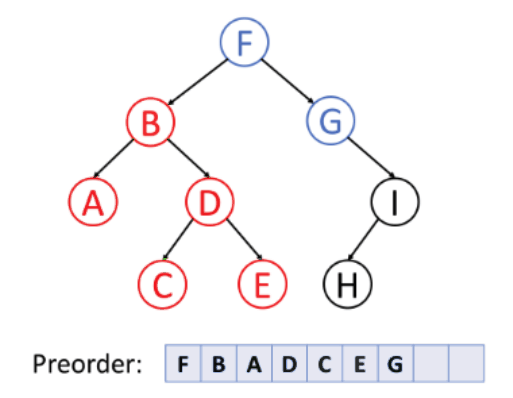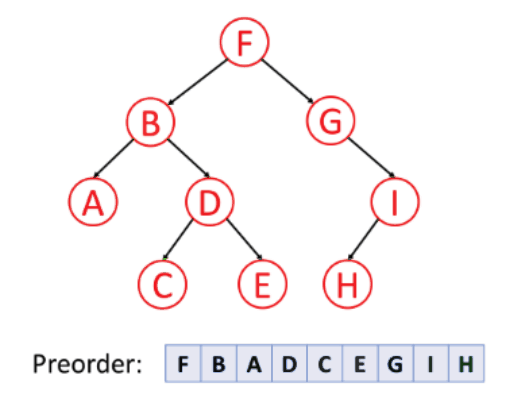
1. 전위 순회
루트 노드 - 왼쪽 - 오른쪽 순서로 순회하는 방식이다.
다른 말로 깊이 우선 탐색(DFS, Depth First Search)라고 불린다.
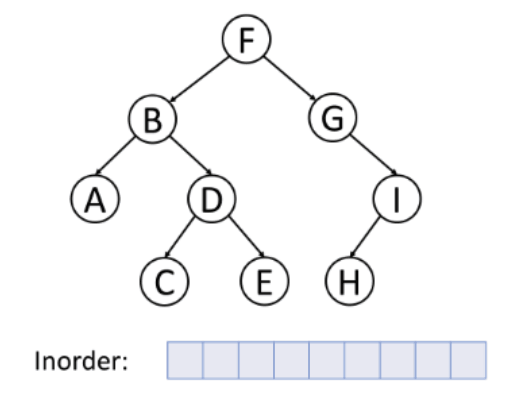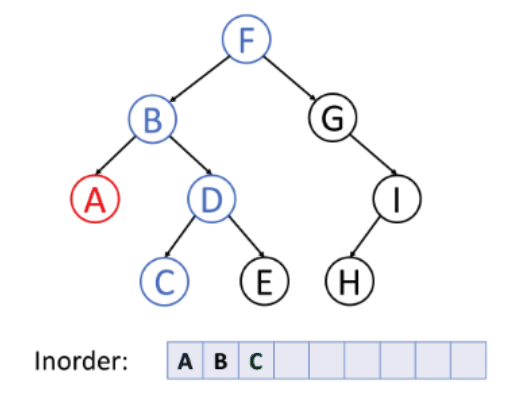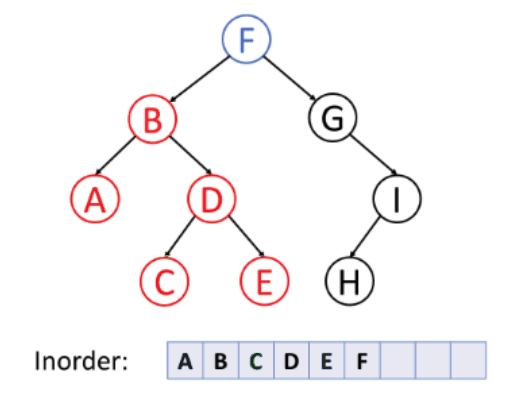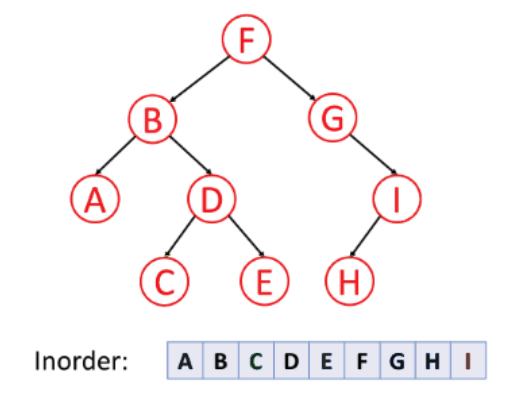
2. 중위 순회
왼쪽 - 노드 - 오른쪽 순서로 순회하는 방식이다.
다른 말로 대칭 순회라고 불린다.
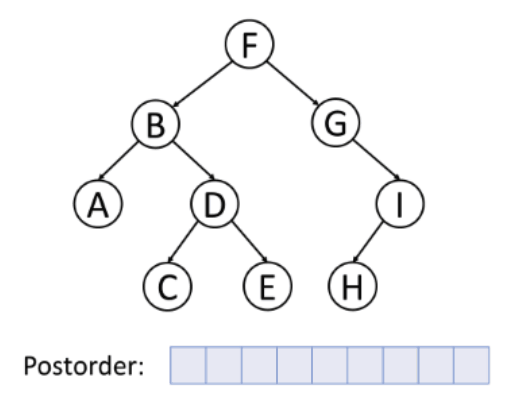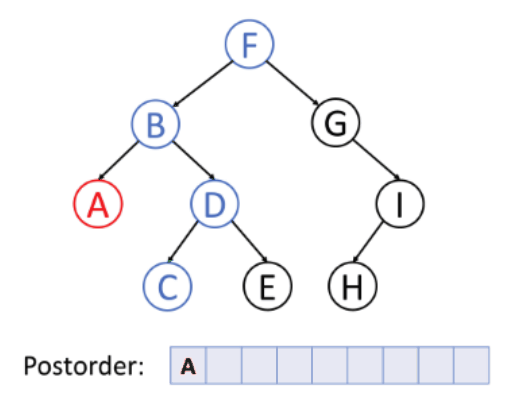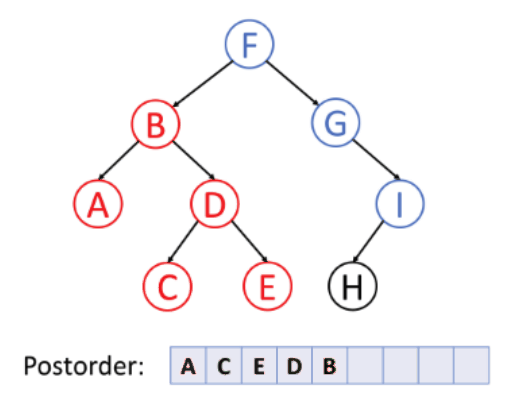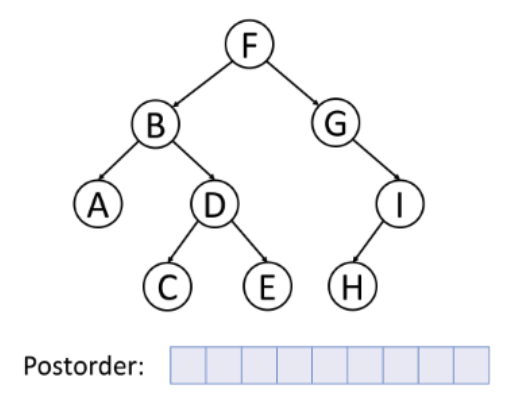
3. 후위 순회
왼쪽 - 오른쪽 - 노드 순서로 순회하는 방식이다.
트리 사용 예시
트리의 주된 목적은 탐색(Search)에 있다.
따라서 아래의 예시에서 트리가 자주 사용된다.
- 파일 시스템(Directory structure)
- 검색 엔진
- 라우터 알고리즘
- 계층적 데이터를 다룰 때 사용됨
트리 C++ STL
이전 해시테이블에서 언급되었듯이 tree구조는 C++에서 <map>을 이용한다.
따라서 트리이자 노드 기반으로 이루어져있고, 해시랑 같이 key-value의 쌍으로 이루어져 있다.
map의 특징
- 크기가 가변적이다.
- 데이터 삽입 시, key를 기준으로 오름차순으로 자동 정렬된다.
- 중복된 key를 사용하고 싶으면
<multi_map>을 사용하자.
- 중복된 key를 사용하고 싶으면
- 많은 자료를 저장하며 동시에 검색 속도가 빠르다.
map은 트리 구조 기반이기 때문에 데이터의 개수가 N이라고 하면, 검색-삽입-삭제 시간 복잡도가 O(log N)으로 보장되어 있다.
Leave a comment